
Trong bài hướng dẫn này, học cách đọc/giữ liệu vào lakehouse của bạn bằng một notebook. Cả hai API Spark và API Pandas được hỗ trợ để đạt được mục tiêu này.
Tải dữ liệu bằng một API Apache Spark
Trong ô mã nguồn của notebook, sử dụng đoạn mã ví dụ sau để đọc dữ liệu từ nguồn và tải vào các phần Files, Tables hoặc cả hai trong lakehouse của bạn.
Để chỉ định vị trí để đọc từ, bạn có thể sử dụng đường dẫn tương đối nếu dữ liệu đến từ lakehouse mặc định của notebook hiện tại, hoặc bạn có thể sử dụng đường dẫn tuyệt đối ABFS nếu dữ liệu đến từ lakehouse khác. Bạn có thể sao chép đường dẫn này từ menu ngữ cảnh của dữ liệu.
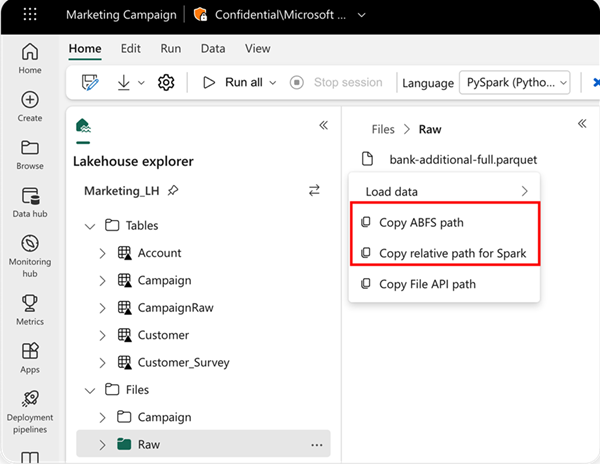
Sao chép đường dẫn ABFS: Điều này trả về đường dẫn tuyệt đối của tệp tin.
Sao chép đường dẫn tương đối cho Spark: Điều này trả về đường dẫn tương đối của tệp tin trong lakehouse mặc định.
Python
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default Lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default Lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default Lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)Tải dữ liệu bằng một API Pandas
Để hỗ trợ API Pandas, lakehouse mặc định sẽ tự động được gắn kết vào sổ tay. Điểm gắn kết là ‘/lakehouse/default/’. Bạn có thể sử dụng điểm gắn kết này để đọc/giữ liệu từ/đến lakehouse mặc định. Tùy chọn “Sao chép đường dẫn API Tệp tin” từ menu ngữ cảnh sẽ trả về đường dẫn API Tệp từ điểm gắn kết đó. Đường dẫn trả về từ tùy chọn Copy ABFS path cũng hoạt động cho API Pandas.
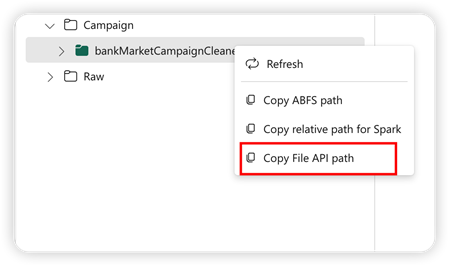
Copy File API Path: Điều này trả về đường dẫn dưới điểm gắn kết của lakehouse mặc định.
Python
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://[email protected]/Marketing_LH.Lakehouse/Files/sample.parquet")Mẹo Đối với API Spark, vui lòng sử dụng tùy chọn Copy ABFS path hoặc Copy relative path for Spark để lấy đường dẫn của tệp tin. Đối với API Pandas, vui lòng sử dụng tùy chọn Copy ABFS path hoặc Copy File API path để lấy đường dẫn của tệp tin.
Cách nhanh nhất để có mã nguồn hoạt động với API Spark hoặc API Pandas là sử dụng tùy chọn Load data và chọn API bạn muốn sử dụng. Mã nguồn sẽ tự động được tạo trong ô mã nguồn mới của sổ tay.

Nguồn : https://learn.microsoft.com/en-us/fabric/data-engineering/lakehouse-notebook-load-data

{kind=link}