
OneLake là hồ dữ liệu logic, thống nhất, duy nhất cho toàn bộ tổ chức của bạn. Giống như OneDrive, OneLake tự động đi kèm với mọi đối tượng thuê Microsoft Fabric và được thiết kế để trở thành nơi duy nhất cho tất cả dữ liệu phân tích của bạn. OneLake mang đến cho khách hàng:
- One data lake cho toàn bộ tổ chức
- One copy of data để sử dụng với nhiều công cụ phân tích
Một hồ dữ liệu cho toàn bộ tổ chức
Trước OneLake, khách hàng có thể dễ dàng tạo nhiều lakes cho các nhóm kinh doanh khác nhau hơn là cộng tác trên một lake duy nhất, ngay cả khi phải tốn thêm chi phí quản lý nhiều tài nguyên. OneLake tập trung vào việc loại bỏ những thách thức này bằng cách cải thiện sự cộng tác. Mỗi khách hàng thuê có chính xác một OneLake. Không bao giờ có thể có nhiều hơn một và nếu bạn có Fabric thì không bao giờ có thể có số 0. Mọi đối tượng thuê Fabric đều tự động cung cấp OneLake mà không cần phải thiết lập hoặc quản lý thêm tài nguyên nào.
Được quản lý theo mặc định với quyền sở hữu được phân phối để cộng tác
Khái niệm đối tượng thuê là một lợi ích độc đáo của dịch vụ SaaS. Việc biết tổ chức của khách hàng bắt đầu và kết thúc ở đâu sẽ mang lại ranh giới quản trị và tuân thủ tự nhiên, nằm dưới sự kiểm soát của quản trị viên đối tượng thuê. Mọi dữ liệu đưa vào OneLake đều được quản lý theo mặc định. Mặc dù tất cả dữ liệu đều nằm trong ranh giới do quản trị viên đối tượng thuê đặt ra, nhưng điều quan trọng là quản trị viên này không trở thành người gác cổng trung tâm ngăn cản các bộ phận khác của tổ chức đóng góp cho OneLake.
Trong một đối tượng thuê, bạn có thể tạo bất kỳ số lượng không gian làm việc nào. Không gian làm việc cho phép các bộ phận khác nhau của tổ chức phân phối các chính sách quyền sở hữu và quyền truy cập. Mỗi không gian làm việc là một phần của năng lực được gắn với một khu vực cụ thể và được tính phí riêng.
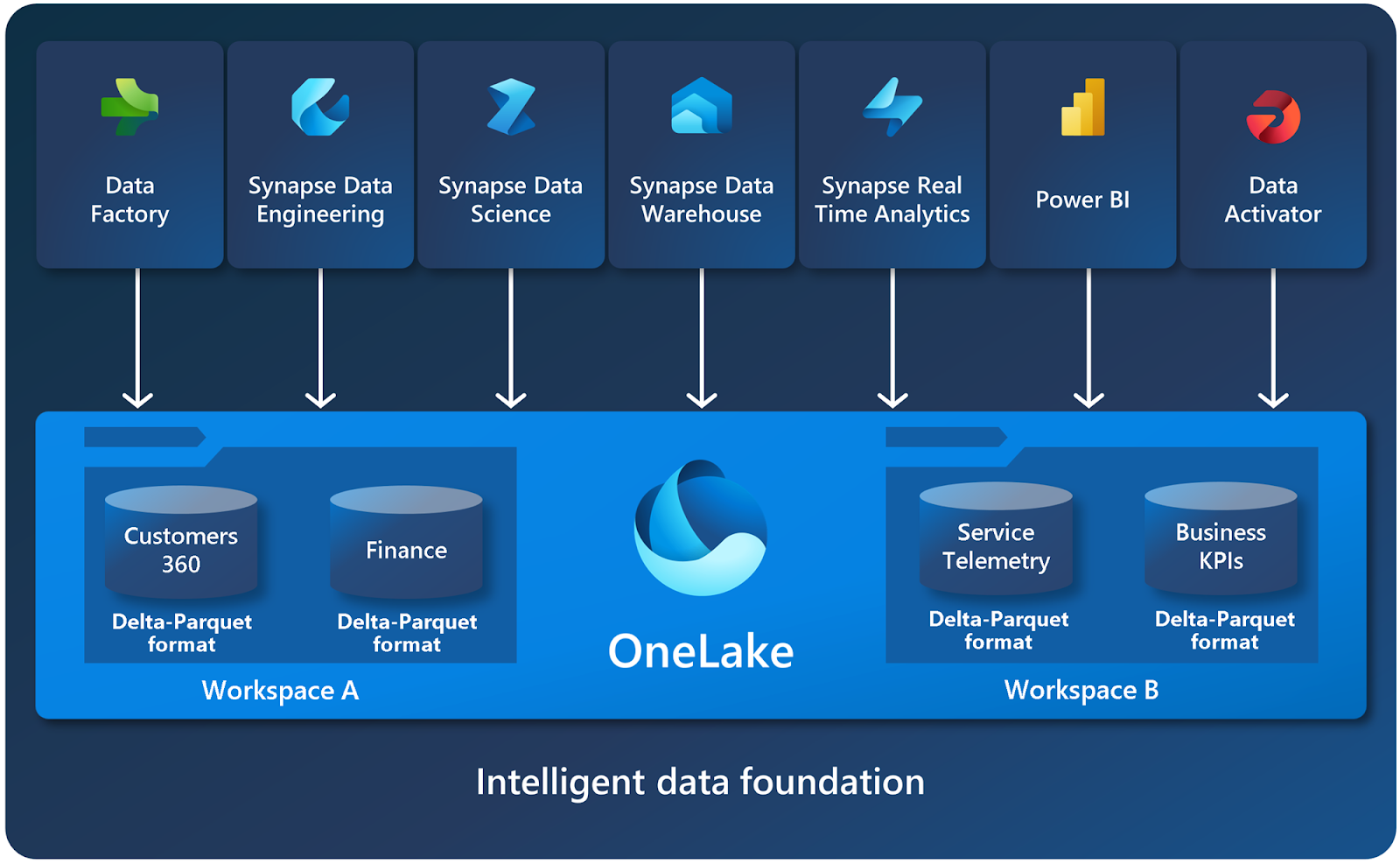
Trong không gian làm việc, bạn có thể tạo các mục dữ liệu và truy cập tất cả dữ liệu trong OneLake thông qua các mục dữ liệu. Tương tự như cách Office lưu trữ các tệp Word, Excel và PowerPoint trong OneDrive, Fabric lưu trữ các ngôi nhà bên hồ, nhà kho và các mục khác trong OneLake. Các vật phẩm có thể mang lại trải nghiệm phù hợp cho từng cá nhân, chẳng hạn như trải nghiệm của nhà phát triển Spark trong một ngôi nhà bên hồ.
Để biết thêm thông tin về cách bắt đầu sử dụng OneLake, hãy xem bài viết này.
Mở ở mọi cấp độ
OneLake mở ở mọi cấp độ. OneLake được xây dựng dựa trên Azure Data Lake Storage (ADLS) Gen2 và có thể hỗ trợ mọi loại tệp, có cấu trúc hoặc không cấu trúc. Tất cả các mục dữ liệu Fabric như kho dữ liệu và nhà lưu trữ hồ đều tự động lưu trữ dữ liệu của chúng trong OneLake ở định dạng Delta Parquet. Nếu một kỹ sư dữ liệu tải dữ liệu vào một kho dữ liệu bằng Spark và sau đó nhà phát triển SQL sử dụng T-SQL để tải dữ liệu trong kho dữ liệu giao dịch đầy đủ thì cả hai đều đang đóng góp vào cùng một hồ dữ liệu. OneLake lưu trữ tất cả dữ liệu dạng bảng ở định dạng Delta Parquet.
OneLake hỗ trợ các API và SDK ADLS Gen2 tương tự để tương thích với các ứng dụng ADLS Gen2 hiện có, bao gồm cả Azure Databricks. Bạn có thể xử lý dữ liệu trong OneLake như thể đó là một tài khoản lưu trữ ADLS lớn cho toàn bộ tổ chức. Mọi không gian làm việc xuất hiện dưới dạng vùng chứa trong tài khoản lưu trữ đó và các mục dữ liệu khác nhau xuất hiện dưới dạng thư mục trong các vùng chứa đó.
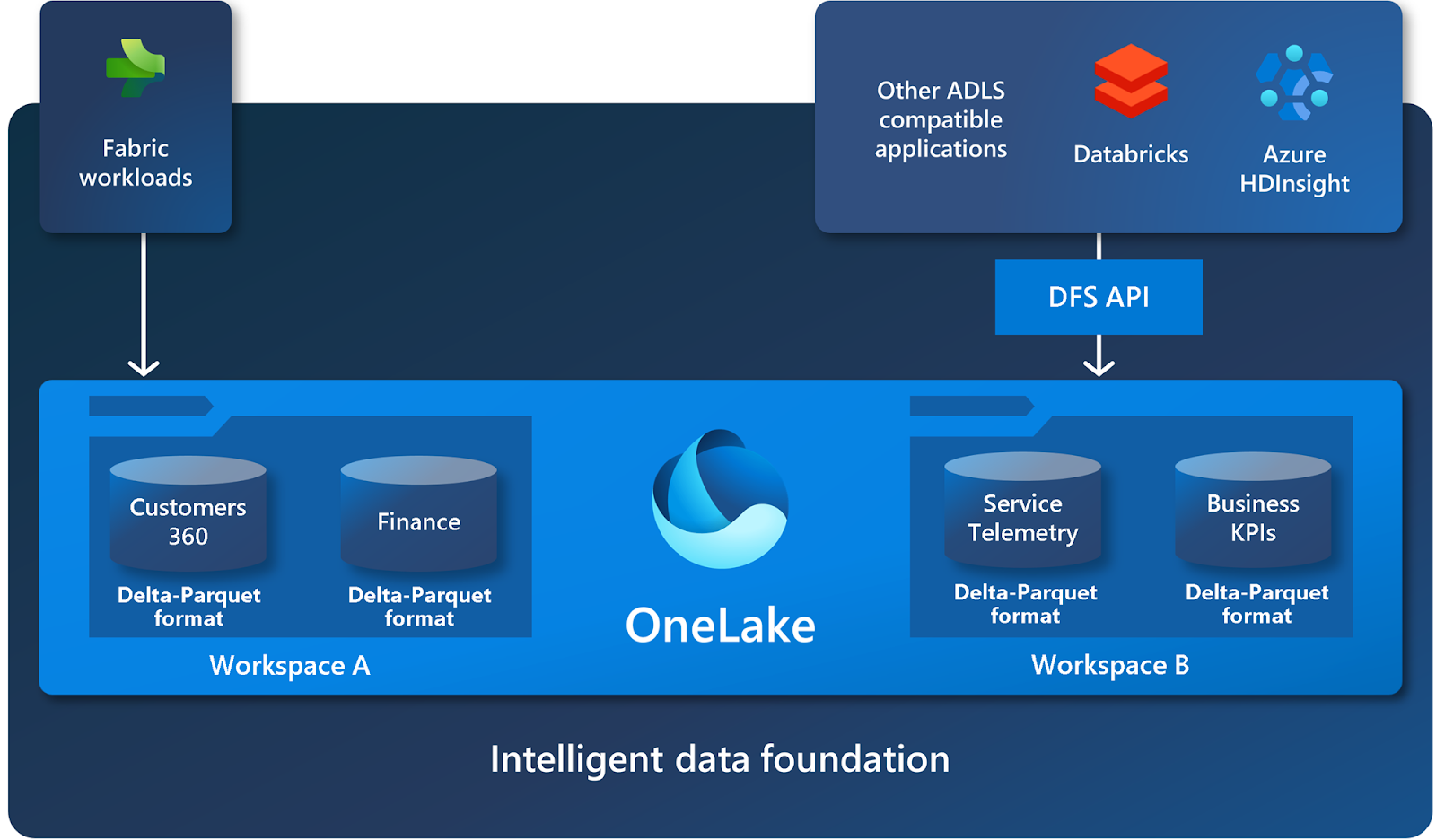
Để biết thêm thông tin về API và điểm cuối, hãy xem quyền truy cập và API của OneLake.
Trình khám phá tệp OneLake cho Windows
OneLake là OneDrive dành cho dữ liệu. Giống như OneDrive, bạn có thể dễ dàng khám phá dữ liệu OneLake từ Windows bằng trình khám phá tệp OneLake dành cho Windows. Bạn có thể điều hướng tất cả các không gian làm việc và mục dữ liệu của mình, dễ dàng tải lên, tải xuống hoặc sửa đổi tệp giống như bạn làm trong Office. Trình thám hiểm tệp OneLake đơn giản hóa hoạt động với các hồ dữ liệu, cho phép ngay cả những người dùng doanh nghiệp không có kỹ thuật cũng có thể sử dụng chúng.
Để biết thêm thông tin, hãy xem trình khám phá tệp OneLake .
Một bản sao dữ liệu
OneLake nhằm mục đích cung cấp cho bạn giá trị cao nhất có thể từ một bản sao dữ liệu mà không cần di chuyển hoặc sao chép dữ liệu. Bạn không còn cần phải sao chép dữ liệu chỉ để sử dụng nó với một công cụ khác hoặc phá vỡ các silo để có thể phân tích dữ liệu với dữ liệu từ các nguồn khác.
Phím tắt kết nối dữ liệu giữa các miền mà không cần di chuyển dữ liệu
Phím tắt cho phép tổ chức của bạn dễ dàng chia sẻ dữ liệu giữa người dùng và ứng dụng mà không cần phải di chuyển và sao chép thông tin một cách không cần thiết. Khi các nhóm làm việc độc lập trong không gian làm việc riêng biệt, các phím tắt cho phép bạn kết hợp dữ liệu giữa các nhóm và miền kinh doanh khác nhau thành một sản phẩm dữ liệu ảo phù hợp với nhu cầu cụ thể của người dùng.
Phím tắt là tham chiếu đến dữ liệu được lưu trữ ở các vị trí tệp khác. Các vị trí tệp này có thể nằm trong cùng một không gian làm việc hoặc trên các không gian làm việc khác nhau, trong OneLake hoặc bên ngoài OneLake trong ADLS, S3 hoặc Dataverse — sắp có nhiều vị trí mục tiêu hơn. Bất kể vị trí, các phím tắt làm cho các tệp và thư mục trông giống như bạn đã lưu trữ chúng cục bộ.
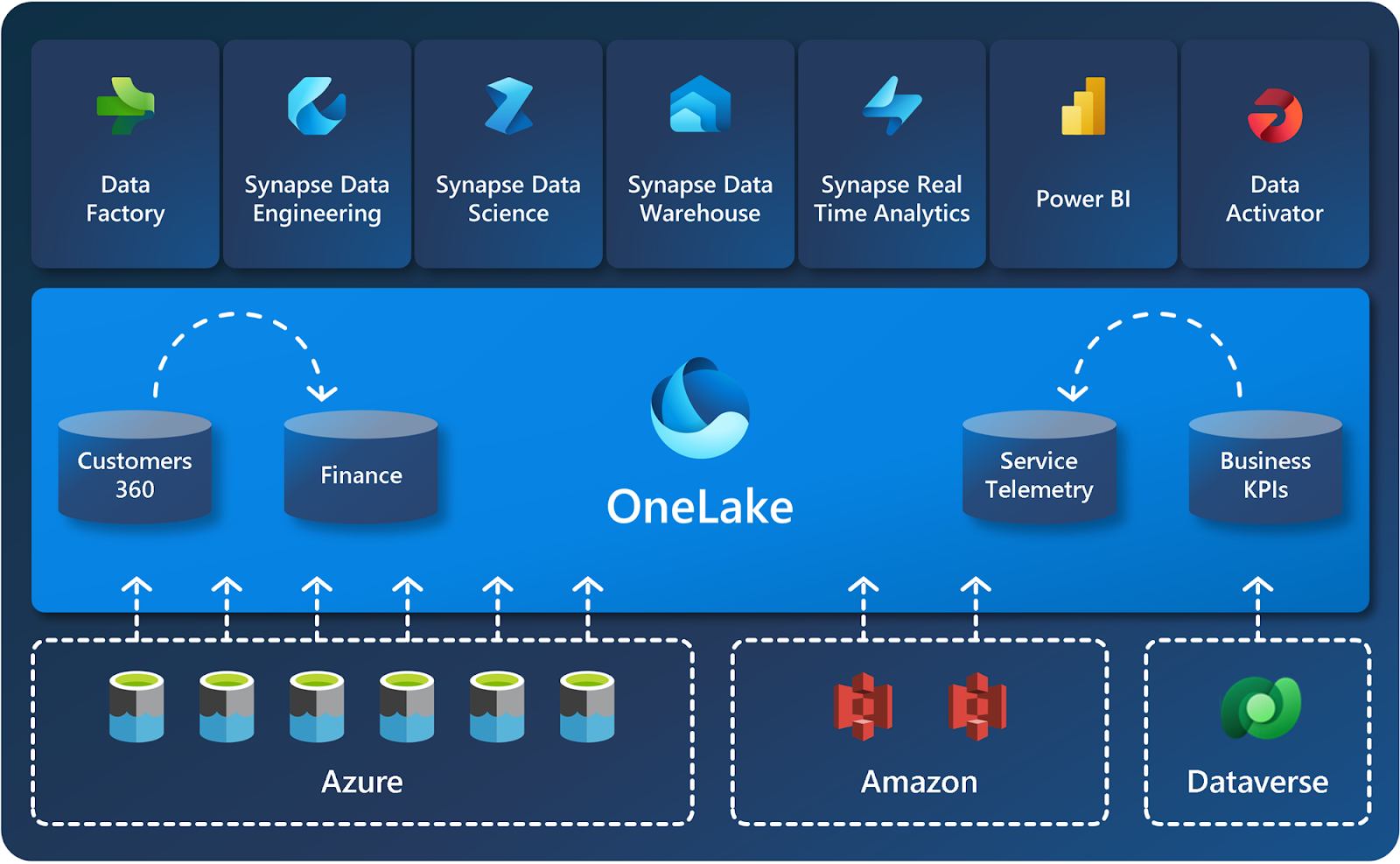
Để biết thêm thông tin về cách sử dụng phím tắt, hãy xem Phím tắt OneLake .
Một bản sao dữ liệu với nhiều công cụ phân tích
Mặc dù các ứng dụng có thể có sự tách biệt về lưu trữ và tính toán, nhưng dữ liệu thường được tối ưu hóa cho một công cụ duy nhất, điều này gây khó khăn cho việc sử dụng lại cùng một dữ liệu cho nhiều ứng dụng. Với Fabric, các công cụ phân tích khác nhau (T-SQL, Spark, Dịch vụ phân tích, v.v.) lưu trữ dữ liệu ở định dạng Delta Parquet mở để cho phép bạn sử dụng cùng một dữ liệu trên nhiều công cụ.
Không còn cần phải sao chép dữ liệu chỉ để sử dụng nó với một công cụ khác. Bạn luôn có thể chọn công cụ tốt nhất cho công việc mà bạn đang cố gắng thực hiện. Ví dụ: hãy tưởng tượng bạn có một nhóm kỹ sư SQL đang xây dựng kho dữ liệu giao dịch đầy đủ. Họ có thể sử dụng công cụ T-SQL và tất cả sức mạnh của T-SQL để tạo bảng, chuyển đổi dữ liệu và tải dữ liệu vào bảng. Nếu một nhà khoa học dữ liệu muốn sử dụng dữ liệu này, họ không cần phải thông qua trình điều khiển Spark/SQL đặc biệt nữa. OneLake lưu trữ tất cả dữ liệu ở định dạng Delta Parquet. Các nhà khoa học dữ liệu có thể sử dụng toàn bộ sức mạnh của công cụ Spark và các thư viện nguồn mở của nó trực tiếp trên dữ liệu.
Người dùng doanh nghiệp có thể xây dựng báo cáo Power BI trực tiếp trên OneLake bằng chế độ Direct Lake mới trong công cụ Dịch vụ phân tích. Công cụ Dịch vụ Phân tích là công cụ hỗ trợ các mô hình ngữ nghĩa Power BI và nó luôn cung cấp hai chế độ truy cập dữ liệu: nhập và truy vấn trực tiếp. Chế độ Direct Lake mang đến cho người dùng toàn bộ tốc độ nhập mà không cần sao chép dữ liệu, kết hợp tốt nhất giữa nhập và truy vấn trực tiếp.
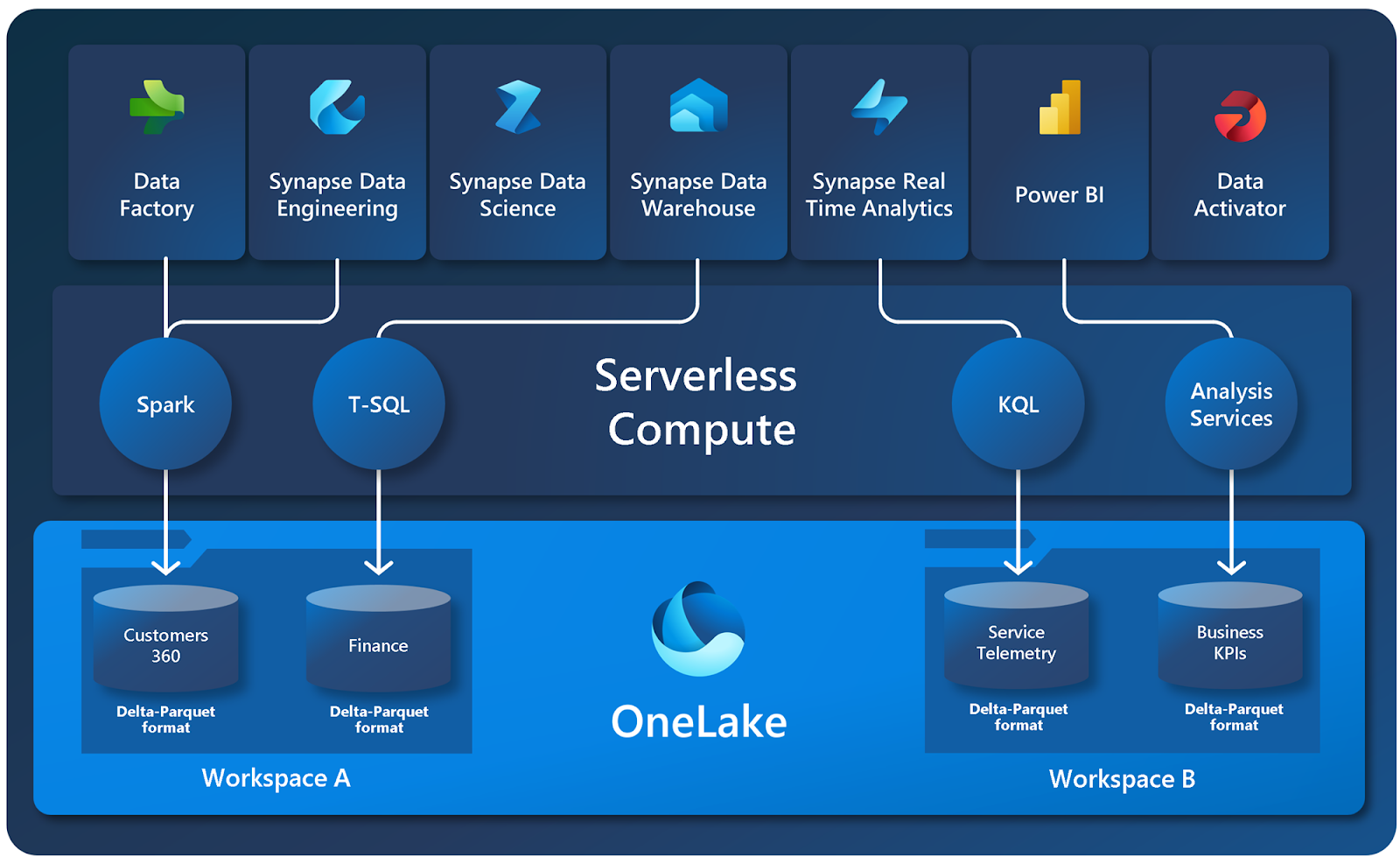
Sơ đồ ví dụ hiển thị việc tải dữ liệu bằng Spark, truy vấn bằng T-SQL và xem dữ liệu trong báo cáo Power BI.
Nguồn: https://learn.microsoft.com/en-us/fabric/onelake/onelake-overview

{kind=link}