
Data pipelines cung cấp một phương thức thay thế cho việc sử dụng lệnh COPY thông qua giao diện người dùng đồ họa. Một Data pipelines là một nhóm logic của các hoạt động kết hợp để thực hiện một nhiệm vụ nhập dữ liệu. Các pipelines cho phép bạn quản lý các hoạt động trích xuất, biến đổi và tải (ETL) thay vì quản lý từng hoạt động cá nhân.
Trong hướng dẫn này, bạn sẽ tạo một pipelines mới để tải dữ liệu mẫu vào một warehouse trong Microsoft Fabric.
Tạo một đường dẫn dữ liệu
- Để tạo một pipelines mới, điều hướng đến không gian làm việc của bạn, chọn nút +New, và sau đó chọn Data pipeline.
- Trong hộp thoại New pipeline, cung cấp tên cho pipelines mới của bạn và chọn Create.
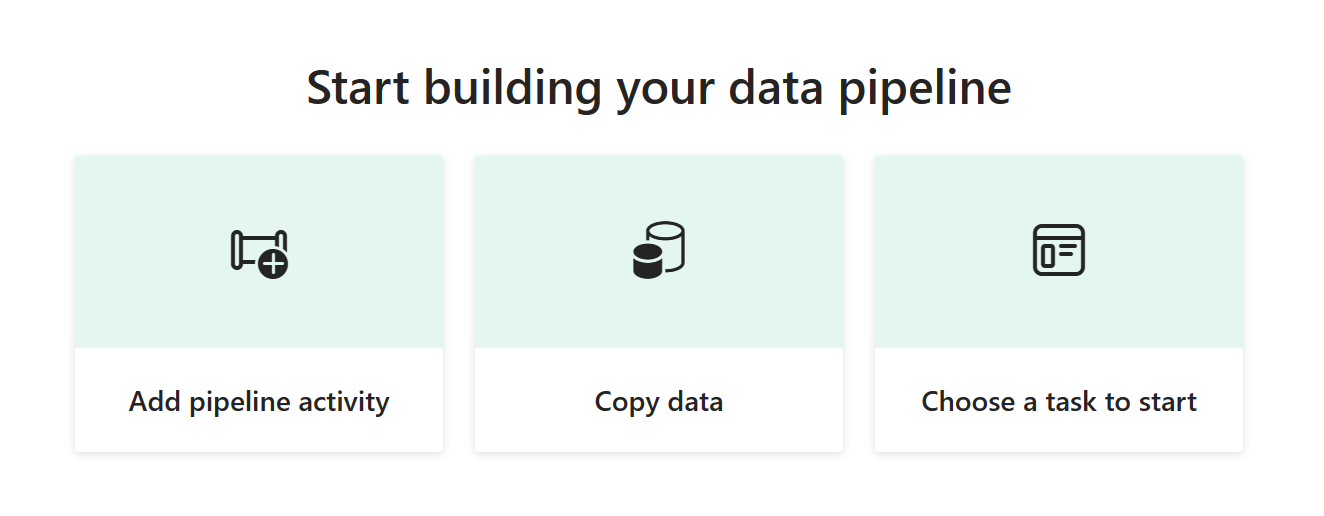
- Bạn sẽ đến khu vực bảng vẽ pipelines, nơi bạn sẽ thấy ba tùy chọn để bắt đầu: Thêm một hoạt động pipelines, Sao chép dữ liệu và Chọn một nhiệm vụ để bắt đầu.
Mỗi tùy chọn này cung cấp các lựa chọn khác nhau để tạo một pipelines:- Add pipeline activity:Tùy chọn này mở trình soạn thảo pipelines, nơi bạn có thể tạo các pipelines mới từ đầu bằng cách sử dụng các hoạt động pipelines. Copy data: Tùy chọn này mở một trợ lý từng bước giúp bạn chọn nguồn dữ liệu, đích và cấu hình các tùy chọn tải dữ liệu như ánh xạ cột. Khi hoàn thành, nó tạo một hoạt động pipelines mới với một nhiệm vụ Sao chép Dữ liệu đã được cấu hình sẵn cho bạn. Choose a task to start: Tùy chọn này mở một bộ mẫu được xác định trước để giúp bạn bắt đầu với các pipelines dựa trên các tình huống khác nhau.
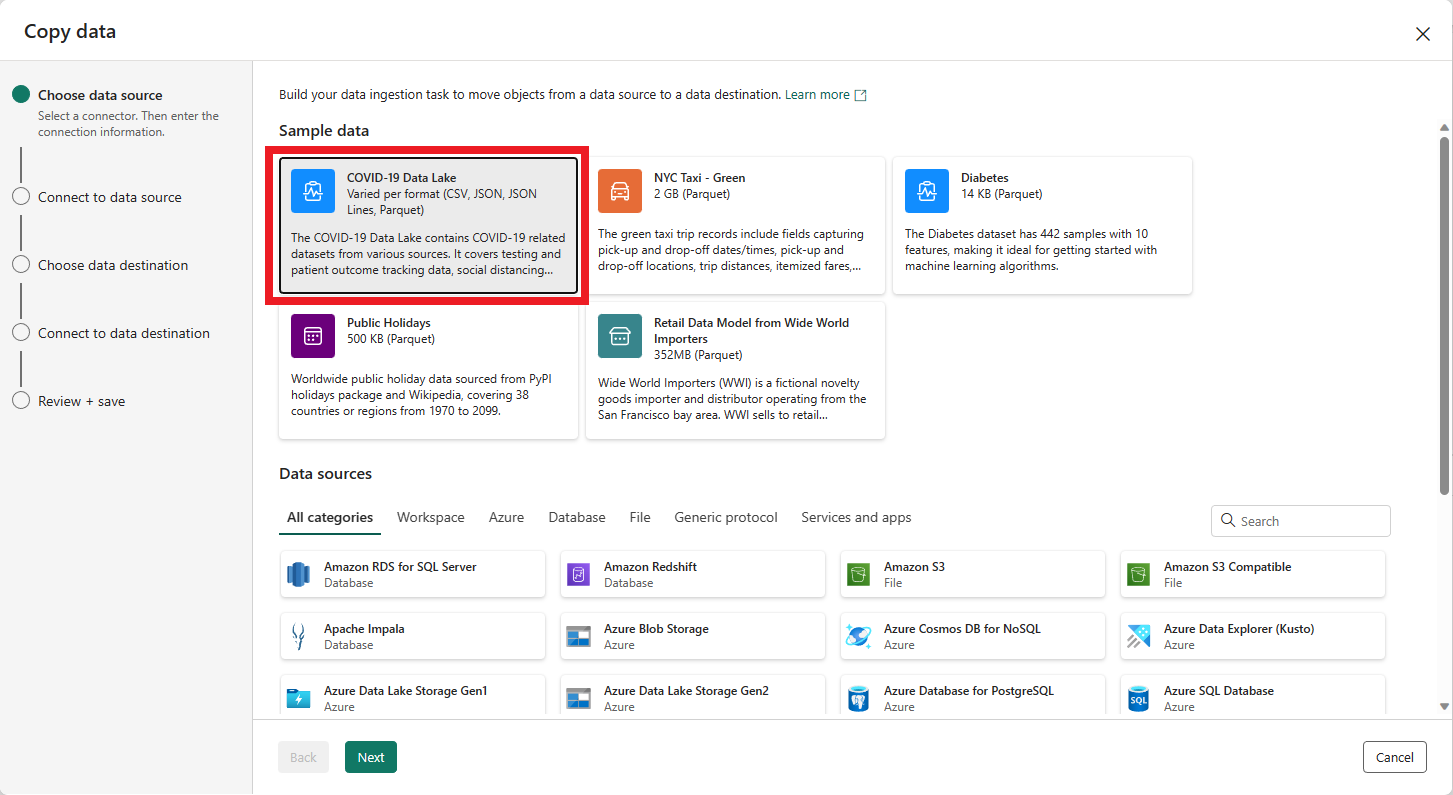
- Trang đầu tiên của Trợ lý Sao chép dữ liệu giúp bạn chọn dữ liệu của mình từ nhiều nguồn dữ liệu khác nhau hoặc chọn từ một trong các mẫu đã được cung cấp để bắt đầu. Đối với hướng dẫn này, chúng ta sẽ sử dụng Mẫu Dữ liệu Lake COVID-19. Chọn tùy chọn này và chọn Tiếp theo.
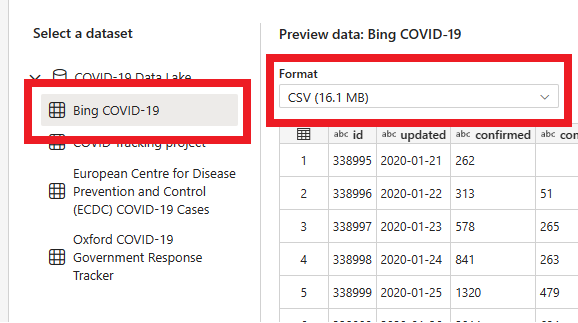
- Trong trang tiếp theo, bạn có thể chọn một bộ dữ liệu, định dạng tệp nguồn và xem trước bộ dữ liệu đã chọn. Chọn Bing COVID-19, định dạng CSV và chọn Tiếp theo.
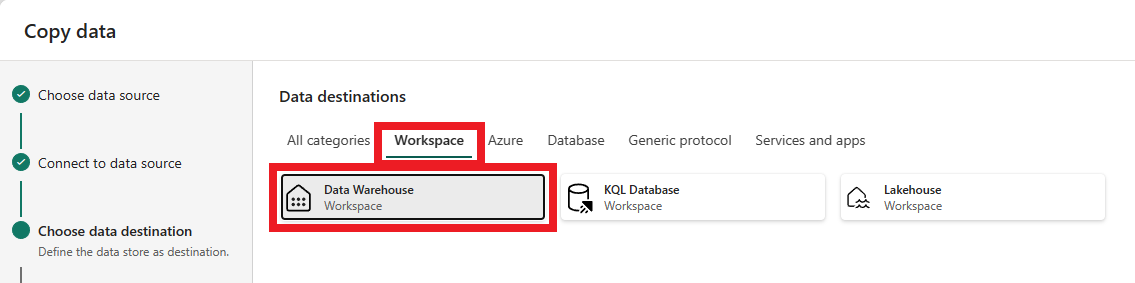
- Trang tiếp theo,Data destinations, cho phép bạn cấu hình loại không gian làm việc đích. Chúng ta sẽ tải dữ liệu vào một warehouse lưu trữ trong không gian làm việc của chúng ta, vì vậy chọn tab Warehouse và tùy chọn Data Warehouse. Chọn Next.
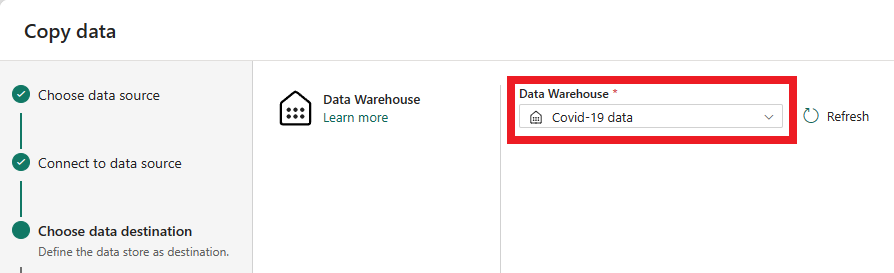
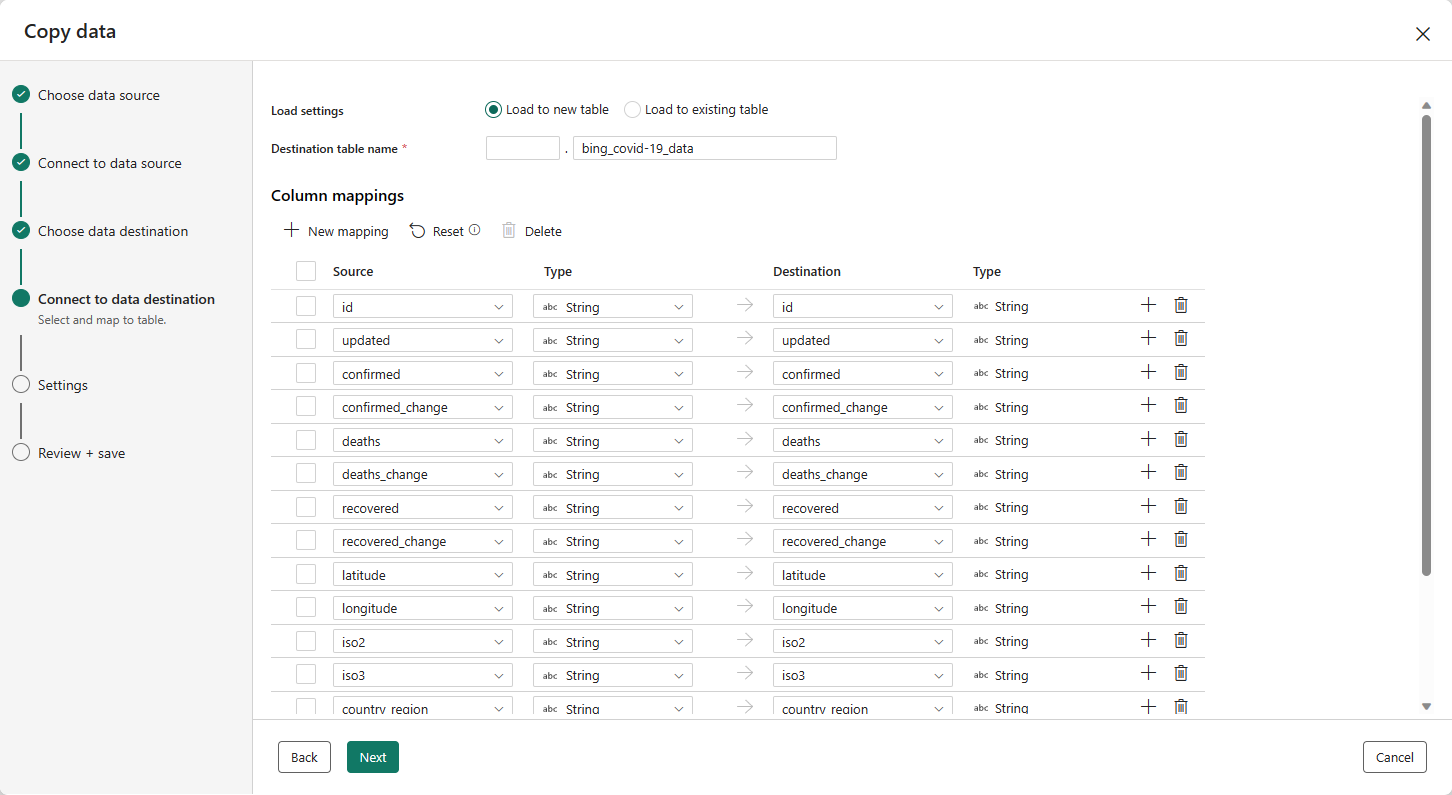
Bây giờ là lúc chọn warehouse để tải dữ liệu vào. Chọn warehouse mong muốn của bạn trong hộp thoại thả xuống và chọn Next. - Bước cuối cùng để cấu hình đích là cung cấp tên cho bảng đích và cấu hình ánh xạ cột. Ở đây, bạn có thể chọn tải dữ liệu vào một bảng mới hoặc một bảng đã tồn tại, cung cấp tên schema và tên bảng, thay đổi tên cột, loại bỏ cột hoặc thay đổi ánh xạ của chúng. Bạn có thể chấp nhận giá trị mặc định hoặc điều chỉnh các thiết lập theo sở thích của bạn.
- Khi bạn đã xem xét xong các tùy chọn, chọn Next.
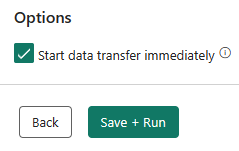
Trang tiếp theo cho bạn lựa chọn sử dụng khu vực tạm, hoặc cung cấp các tùy chọn nâng cao cho hoạt động sao chép dữ liệu (sử dụng lệnh T-SQL COPY). Xem xét các tùy chọn mà không thay đổi chúng và chọn Next. - Trang cuối cùng trong trợ lý cung cấp một tóm tắt về hoạt động sao chép. Chọn lựa chọn Start data transfer immediately và chọn Save + Run.
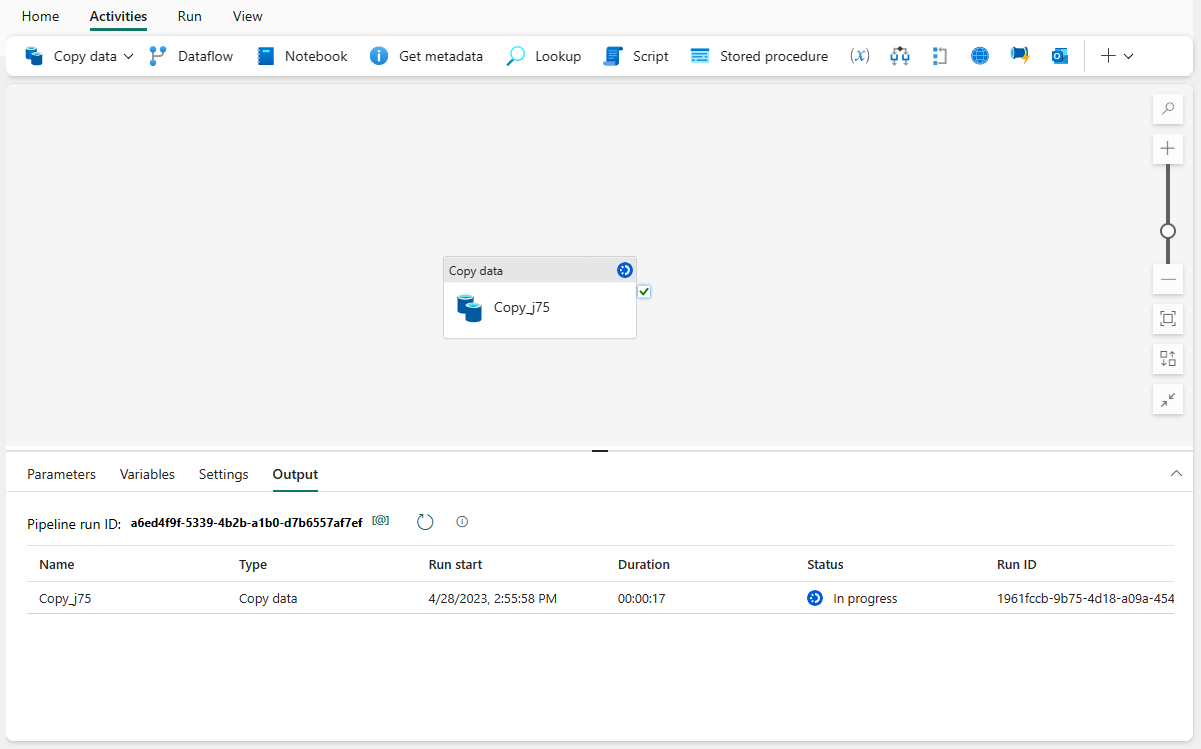
- Bạn sẽ được chuyển đến khu vực bảng vẽ pipelines, nơi đã có một hoạt động Sao chép Dữ liệu mới được cấu hình sẵn cho bạn. pipelines sẽ bắt đầu chạy tự động. Bạn có thể theo dõi trạng thái của pipelines của mình trong cửa sổ Output:
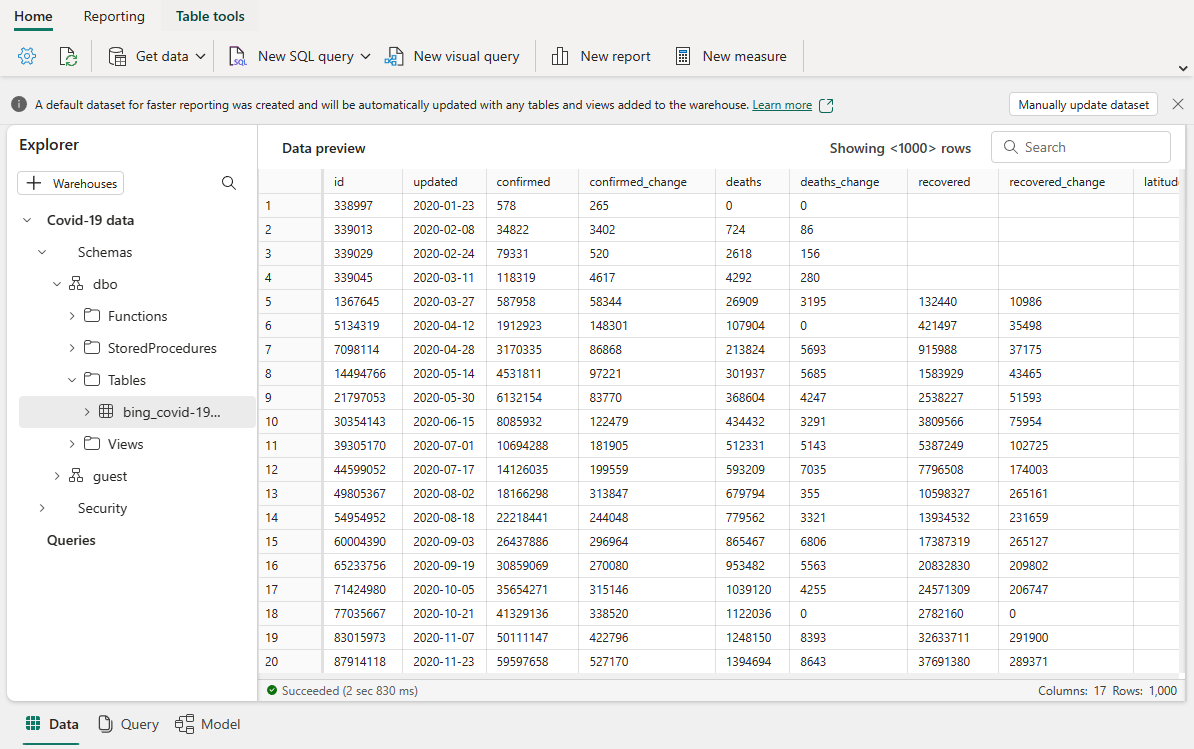
- Sau vài giây, pipelines của bạn sẽ hoàn thành mà không gặp sự cố. Để xem dữ liệu và xác nhận rằng hoạt động sao chép đã kết thúc, hãy quay lại warehouse của bạn và chọn bảng của bạn để xem trước dữ liệu.
Để biết thêm về việc nhập dữ liệu vào Warehouse của bạn trong Microsoft Fabric, hãy truy cập:
Nguồn: https://learn.microsoft.com/en-us/fabric/data-warehouse/ingest-data-pipeline

{kind=link}