
Lấy dữ liệu từ hồ dữ liệu là một hoạt động đầu vào/đầu ra (IO) quan trọng với những ảnh hưởng đáng kể đối với hiệu suất truy vấn. Trong Microsoft Fabric, Synapse Data Warehouse sử dụng các mô hình truy cập tinh tế để tăng cường việc đọc dữ liệu từ bộ nhớ và nâng cao tốc độ thực thi truy vấn. Ngoài ra, nó giảm thiểu thông minh sự cần thiết của việc đọc từ bộ nhớ lưu trữ từ xa bằng cách tận dụng bộ nhớ đệm cục bộ.
Bộ nhớ đệm là một kỹ thuật cải thiện hiệu suất của các ứng dụng xử lý dữ liệu bằng cách giảm thiểu các thao tác IO. Bộ nhớ đệm lưu trữ dữ liệu và siêu dữ liệu được truy cập thường xuyên ở một tầng lưu trữ nhanh hơn, chẳng hạn như bộ nhớ cục bộ hoặc ổ đĩa SSD cục bộ, để các yêu cầu tiếp theo có thể được phục vụ nhanh chóng hơn, trực tiếp từ bộ nhớ đệm. Nếu một tập dữ liệu cụ thể đã được truy cập trước đây bởi một truy vấn, bất kỳ truy vấn sau này nào cũng sẽ truy xuất dữ liệu đó trực tiếp từ bộ nhớ đệm trong.
Phương pháp này giảm đáng kể độ trễ IO, vì các hoạt động bộ nhớ cục bộ nổi bật nhanh hơn so với việc lấy dữ liệu từ bộ nhớ lưu trữ từ xa.
Quá trình đệm hoàn toàn trong suốt đối với người dùng. Bất kể nguồn gốc là bảng kho, một phím tắt OneLake, hoặc thậm chí là phím tắt OneLake tham chiếu đến các dịch vụ không phải là Azure, truy vấn sẽ đệm toàn bộ dữ liệu mà nó truy cập.
Có hai loại bộ nhớ đệm được mô tả chi tiết hơn trong bài viết này:
Bộ nhớ cache
Khi truy vấn truy cập và lấy dữ liệu từ lưu trữ, nó thực hiện một quá trình biến đổi chuyển mã dữ liệu từ định dạng dựa trên tệp gốc của nó thành cấu trúc được tối ưu hóa cao trong bộ nhớ cache.

Dữ liệu trong bộ nhớ đệm được tổ chức theo định dạng cột nén tối ưu hóa cho các truy vấn phân tích. Mỗi cột dữ liệu được lưu trữ cùng nhau, riêng biệt với các cột khác, cho phép nén tốt hơn do giá trị dữ liệu tương tự được lưu trữ cùng nhau, dẫn đến giảm đáng kể kích thước bộ nhớ. Khi các truy vấn cần thực hiện các hoạt động trên một cột cụ thể như tổng hợp hoặc lọc, hệ thống có thể hoạt động một cách hiệu quả hơn vì nó không cần xử lý dữ liệu không cần thiết từ các cột khác.
Hơn nữa, việc lưu trữ theo định dạng cột cũng thích hợp cho xử lý song song, có thể làm tăng đáng kể tốc độ thực hiện truy vấn đối với các bộ dữ liệu lớn. Hệ thống có thể thực hiện các hoạt động trên nhiều cột đồng thời, tir lợi từ các bộ xử lý đa lõi hiện đại.
Phương pháp này đặc biệt hữu ích cho các khối công việc phân tích nơi mà các truy vấn liên quan đến quét lượng lớn dữ liệu để thực hiện tổng hợp, lọc và các thao tác xử lý dữ liệu khác.
Cache đĩa
Một số bộ dữ liệu cụ thể quá lớn để chứa trong bộ nhớ đệm. Để duy trì hiệu suất truy vấn nhanh chóng cho những bộ dữ liệu này, Warehouse sử dụng không gian đĩa như một phần mở rộng bổ sung cho bộ nhớ đệm. Mọi thông tin được tải vào bộ nhớ đệm cũng được tuần tự hóa vào bộ nhớ đệm SSD.
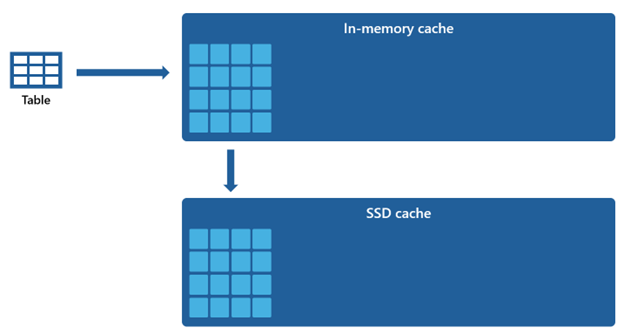
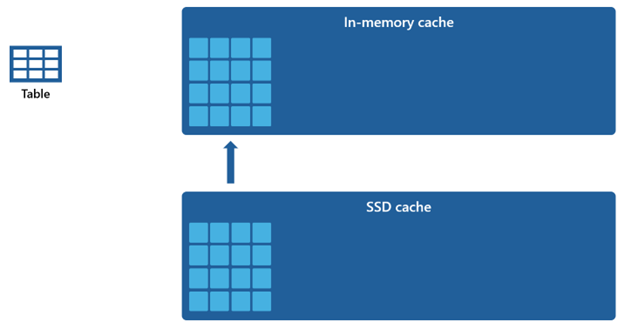
Vì bộ nhớ đệm trong bộ nhớ có dung lượng nhỏ hơn so với bộ nhớ đệm SSD, dữ liệu bị xóa khỏi bộ nhớ đệm trong bộ nhớ vẫn được giữ lại trong bộ nhớ đệm SSD trong một khoảng thời gian mở rộng. Khi các truy vấn sau đó yêu cầu dữ liệu này, nó sẽ được truy xuất từ bộ nhớ đệm SSD vào bộ nhớ đệm trong bộ nhớ ở một tốc độ đáng kể nhanh hơn so với việc lấy từ bộ nhớ lưu trữ từ xa. Điều này cuối cùng mang lại hiệu suất truy vấn ổn định hơn cho bạn.
Quản lý Cache
Bộ nhớ đệm duy trì hoạt động một cách nhất quán và hoạt động mượt mà trong nền, không đòi hỏi sự can thiệp từ bạn. Tắt chức năng đệm không cần thiết, vì điều này sẽ dẫn đến sự suy giảm đáng kể trong hiệu suất truy vấn.
Cơ chế đệm được điều phối và duy trì bởi chính Microsoft Fabric, và nó không cung cấp khả năng cho người dùng để xóa bộ nhớ đệm bằng tay.
Tính nhất quán toàn bộ của các giao dịch đệm đảm bảo rằng bất kỳ sửa đổi nào đối với dữ liệu trong bộ nhớ lưu trữ, chẳng hạn như thông qua các hoạt động Ngôn ngữ Thao tác Dữ liệu (DML), sau khi ban đầu được tải vào bộ nhớ đệm trong bộ nhớ, sẽ dẫn đến dữ liệu nhất quán.
Khi bộ nhớ đệm đạt đến ngưỡng dung lượng của mình và dữ liệu mới đang được đọc lần đầu tiên, các đối tượng không được sử dụng trong thời gian dài nhất sẽ bị loại bỏ khỏi bộ nhớ đệm. Quy trình này được thực hiện để tạo không gian cho luồng dữ liệu mới và duy trì chiến lược tận dụng bộ nhớ đệm tối ưu.
Nguồn: https://learn.microsoft.com/en-us/fabric/data-warehouse/caching

{kind=link}