
Microsoft Fabric cung cấp trải nghiệm Data Science để trang bị người dùng với khả năng hoàn tất các luồng công việc khoa học dữ liệu từ đầu đến cuối với mục đích làm phong phú dữ liệu và tìm hiểu thông tin kinh doanh. Bạn có thể thực hiện một loạt các hoạt động trong toàn bộ quy trình khoa học dữ liệu, từ việc khám phá, chuẩn bị và làm sạch dữ liệu đến thử nghiệm, mô hình hóa, đánh giá mô hình và cung cấp thông tin dự đoán cho các báo cáo BI.
Bạn có thể đã biết về cách thức hoạt động của một quy trình khoa học dữ liệu điển hình. Là một quy trình được biết đến rộng rãi, hầu hết các dự án học máy đều tuân theo nó.
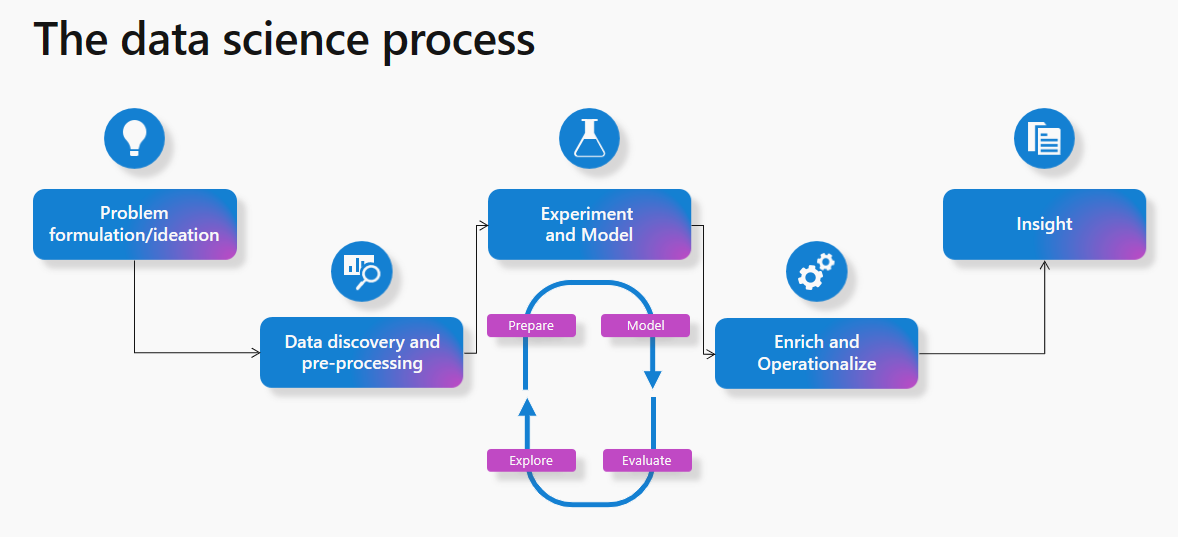
Ở cấp độ cao, quy trình này bao gồm các bước sau:
- Định nghĩa vấn đề và ý tưởng: Xác định vấn đề cần giải quyết và đưa ra các ý tưởng ban đầu về cách sử dụng dữ liệu để giải quyết vấn đề đó.
- Khám phá dữ liệu và tiền xử lý: Thu thập và chuẩn bị dữ liệu cho phân tích.
- Thử nghiệm và mô hình hóa: Xây dựng và đào tạo các mô hình học máy để giải quyết vấn đề.
- Làm giàu và vận hành: Cải thiện và triển khai các mô hình đã được đào tạo vào sản xuất.
- Lấy insights: Trích xuất các hiểu biết sâu sắc từ dữ liệu và sử dụng chúng để cải thiện quyết định.
Bài viết này mô tả các khả năng của Microsoft Fabric Data Science từ góc độ quy trình khoa học dữ liệu. Đối với mỗi bước trong quy trình khoa học dữ liệu, bài viết này tóm tắt các khả năng của Microsoft Fabric có thể trợ giúp.
Định nghĩa vấn đề và ý tưởng
Trong Microsoft Fabric, người dùng khoa học dữ liệu làm việc trên cùng nền tảng với người dùng kinh doanh và nhà phân tích. Điều này giúp việc chia sẻ dữ liệu và cộng tác giữa các vai trò khác nhau trở nên liền mạch hơn. Các nhà phân tích có thể dễ dàng chia sẻ báo cáo Power BI và tập dữ liệu với các chuyên gia khoa học dữ liệu. Sự thuận tiện trong việc cộng tác giữa các vai trò trong Microsoft Fabric giúp việc chuyển giao trong giai đoạn định nghĩa vấn đề dễ dàng hơn nhiều.
Khám phá dữ liệu và tiền xử lý
Người dùng Microsoft Fabric có thể tương tác với dữ liệu trong OneLake bằng cách sử dụng mục Lakehouse. Lakehouse dễ dàng gắn vào Notebook để duyệt và tương tác với dữ liệu.
Người dùng có thể dễ dàng đọc dữ liệu từ Lakehouse trực tiếp vào khung dữ liệu Pandas. Điều này cho phép đọc dữ liệu liền mạch từ OneLake để khám phá.
Bộ công cụ mạnh mẽ cho đường ống thu thập dữ liệu và điều phối dữ liệu có sẵn với đường ống tích hợp dữ liệu – một phần được tích hợp sẵn trong Microsoft Fabric. Các đường ống dữ liệu dễ xây dựng có thể truy cập và chuyển đổi dữ liệu thành định dạng mà máy học có thể sử dụng.
Thử nghiệm và mô hình hóa ML
Với các công cụ như PySpark/Python, SparklyR/R, notebooks có thể xử lý việc đào tạo mô hình machine learning.
Các thuật toán và thư viện ML có thể giúp đào tạo các mô hình machine learning. Công cụ quản lý thư viện có thể cài đặt các thư viện và thuật toán này. Do đó, người dùng có tùy chọn tận dụng nhiều thư viện machine learning phổ biến để hoàn thành việc đào tạo mô hình ML của họ trong Microsoft Fabric.
Ngoài ra, các thư viện phổ biến như Scikit Learn cũng có thể phát triển các mô hình.
Các thử nghiệm và chạy MLflow có thể theo dõi việc đào tạo mô hình ML. Microsoft Fabric cung cấp trải nghiệm MLflow tích hợp mà người dùng có thể tương tác để ghi lại các thử nghiệm và mô hình.
Làm giàu và vận hành
Notebooks có thể xử lý việc đánh giá hàng loạt mô hình machine learning với các thư viện nguồn mở để dự đoán, hoặc chức năng Dự đoán cho Spark phổ biến và có thể mở rộng của Microsoft Fabric, hỗ trợ các mô hình đóng gói MLflow trong đăng ký mô hình Microsoft Fabric.
Lấy insights
Trong Microsoft Fabric, các giá trị được dự đoán có thể dễ dàng được ghi vào OneLake và sử dụng liền mạch từ các báo cáo Power BI, với chế độ Power BI Direct Lake. Điều này giúp các chuyên gia khoa học dữ liệu dễ dàng chia sẻ kết quả công việc của họ với các bên liên quan và cũng đơn giản hóa việc vận hành.
Các notebooks chứa đánh giá hàng loạt có thể được lên lịch để chạy bằng cách sử dụng các chức năng lên lịch của Notebook. Đánh giá hàng loạt cũng có thể được lên lịch như một phần của các hoạt động đường ống dữ liệu hoặc tác vụ Spark. Power BI tự động nhận được các dự đoán mới nhất mà không cần tải hoặc làm mới dữ liệu, nhờ chế độ Direct Lake trong Microsoft Fabric.
Nguồn: https://learn.microsoft.com/en-us/fabric/data-science/data-science-overview

{kind=link}