
Trải nghiệm Khoa học dữ liệu và Kỹ thuật dữ liệu của Microsoft Fabric hoạt động trên nền tảng điện toán Spark được quản lý hoàn toàn. Nền tảng này được thiết kế để mang lại tốc độ và hiệu quả tuyệt vời. Nó bao gồm các nhóm khởi đầu và các nhóm tùy chỉnh.
Môi trường Fabric chứa một tập hợp các cấu hình, bao gồm các thuộc tính điện toán Spark cho phép người dùng định cấu hình phiên Spark sau khi chúng được gắn vào sổ ghi chép và công việc Spark. Với một môi trường, bạn có một cách linh hoạt để tùy chỉnh cấu hình điện toán để chạy các công việc Spark của mình. Trong môi trường, phần điện toán cho phép bạn định cấu hình các thuộc tính cấp phiên Spark để tùy chỉnh bộ nhớ và lõi của người thực thi dựa trên yêu cầu khối lượng công việc.
Quản trị viên Workspace có thể bật hoặc tắt các tùy chỉnh điện toán bằng nút chuyển Customize compute configurations for items trong tab Pool của phần Data Engineering/Science trên màn hình cài đặt Workspace.
Quản trị viên Workspace có thể ủy quyền cho các thành viên và cộng tác viên thay đổi cấu hình điện toán cấp phiên mặc định trong môi trường Fabric bằng cách bật cài đặt này.
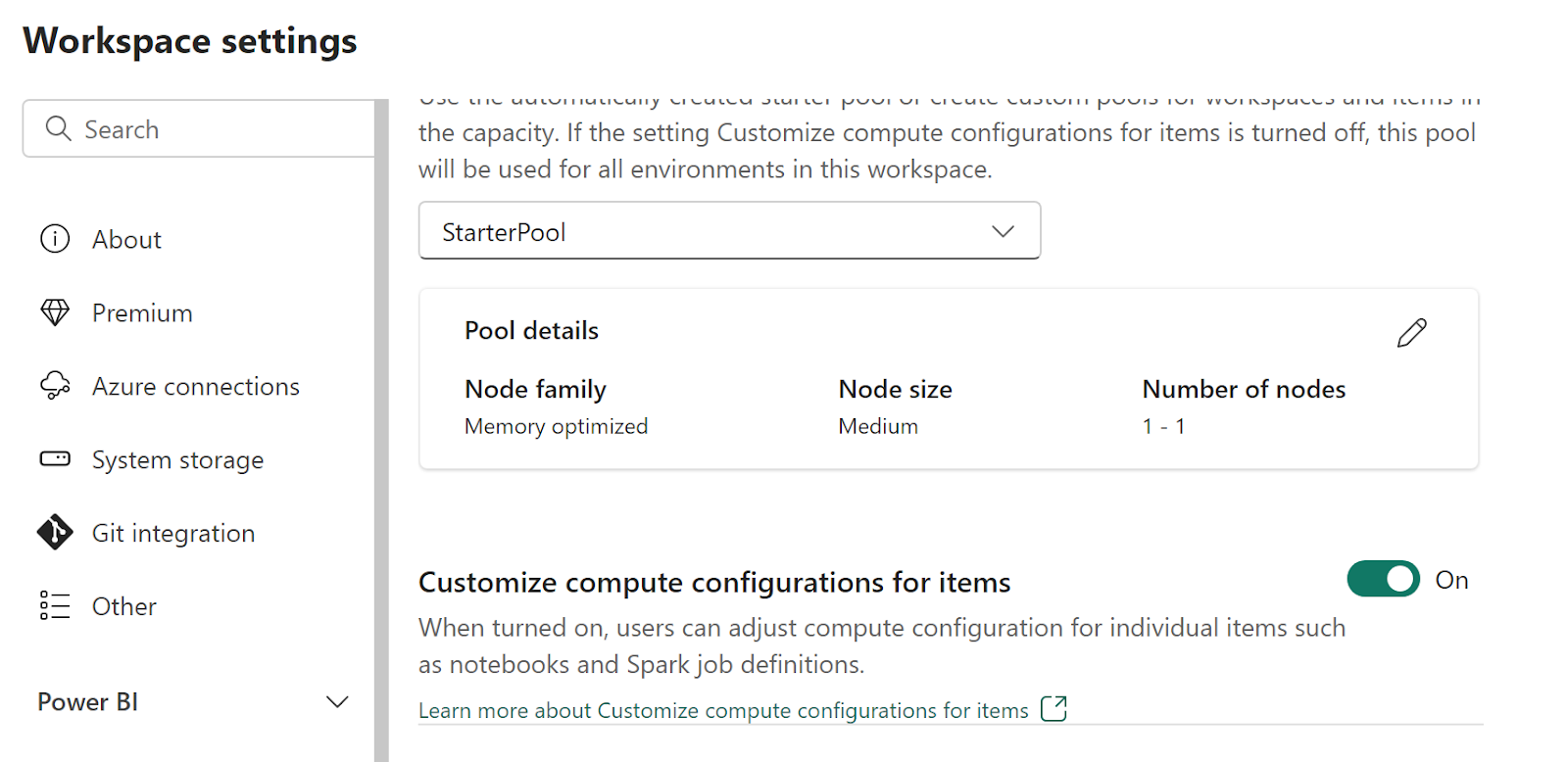
Nếu quản trị viên không gian làm việc tắt tùy chọn này trong cài đặt không gian làm việc, phần điện toán của môi trường sẽ bị tắt và cấu hình điện toán nhóm mặc định cho không gian làm việc sẽ được sử dụng để chạy các công việc Spark.
Tùy chỉnh các thuộc tính tính toán cấp phiên trong môi trường
Với tư cách là người dùng, bạn có thể chọn nhóm cho môi trường từ danh sách các nhóm có sẵn trong không gian làm việc Fabric. Quản trị viên không gian làm việc Fabric tạo nhóm khởi đầu mặc định và nhóm tùy chỉnh.
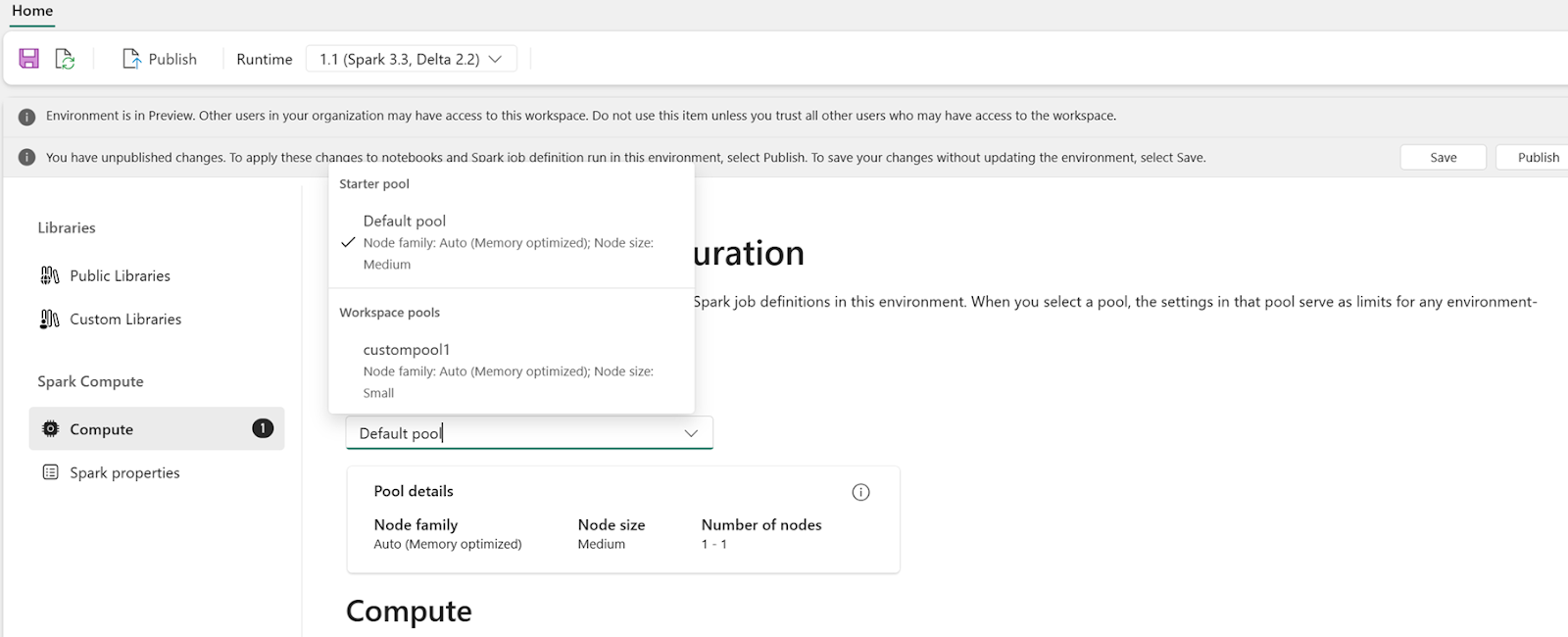
Sau khi chọn một nhóm trong phần Compute, bạn có thể điều chỉnh các lõi và bộ nhớ cho các bộ thực thi trong giới hạn kích thước nút và giới hạn của nhóm đã chọn.
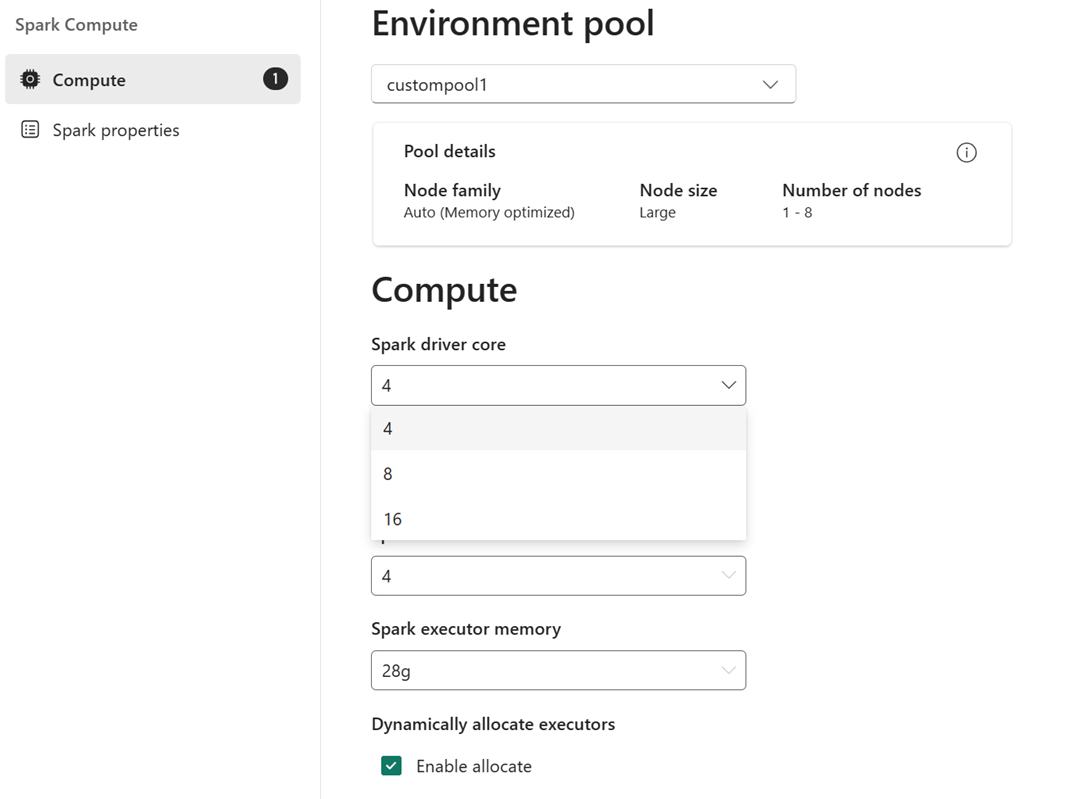
Ví dụ: Bạn chọn một nhóm tùy chỉnh có kích thước nút lớn, là 16 Spark Vcore, làm nhóm môi trường. Sau đó, bạn có thể chọn lõi trình điều khiển/thực thi là 4, 8 hoặc 16, dựa trên yêu cầu cấp độ công việc của bạn. Đối với bộ nhớ được phân bổ cho trình điều khiển và người thực thi, bạn có thể chọn 28 g, 56 g hoặc 112 g, tất cả đều nằm trong giới hạn bộ nhớ nút lớn.
Nguồn: https://learn.microsoft.com/en-us/fabric/data-engineering/environment-manage-compute

{kind=link}