")
Thuật ngữ “dữ liệu lớn” dùng để chỉ các tập dữ liệu lớn, thường được đo bằng terabyte hoặc petabyte, được phân tích để cung cấp thông tin chi tiết về doanh nghiệp. Nó được xác định bởi sự đa dạng của nó (các loại định dạng dữ liệu khác nhau), vận tốc (tốc độ dữ liệu có sẵn) và khối lượng (lượng dữ liệu được thu thập). Dữ liệu lớn có thể bao gồm dữ liệu có cấu trúc, dữ liệu phi cấu trúc và dữ liệu bán cấu trúc, mặc dù dữ liệu có cấu trúc đầy đủ rất hiếm khi xử lý dữ liệu lớn.
Các công ty không còn đủ khả năng để thu thập dữ liệu mà không có được thông tin chi tiết ngay lập tức để có hành động kịp thời và phù hợp. Cho dù đó là thông báo về việc ra quyết định dựa trên dữ liệu, nâng cao hiệu quả hoạt động hay quản lý rủi ro, dữ liệu lớn có thể mang lại lợi thế cạnh tranh lớn.
Bạn muốn tìm hiểu về hoạt động bên trong của dữ liệu lớn và nó có thể giúp ích cho công ty của bạn như thế nào? Chúng tôi đi vào tất cả những điều đó và nhiều hơn nữa dưới đây.
Nguồn gốc của dữ liệu lớn là gì?
Dữ liệu lớn bắt nguồn từ quản lý cơ sở dữ liệu. Mặc dù dữ liệu đã tồn tại hàng thiên niên kỷ, thuật ngữ dữ liệu lớn đã trở nên cần thiết để truyền tải lượng lớn dữ liệu khi khối lượng và tốc độ của dữ liệu vượt quá khả năng của con người. Khi làn sóng thông tin kỹ thuật số bắt đầu tràn vào, các công ty cần tạo ra các công cụ để đảm bảo lưu trữ dữ liệu thành công và tìm ra giá trị trong dữ liệu.
Nhiều tổ chức trong lĩnh vực CNTT, đặc biệt là các tổ chức ở Thung lũng Silicon, đã tập trung vào việc tạo ra các khuôn khổ để xử lý dữ liệu lớn. Các khung này được tạo ra để giải quyết các tình huống trong đó có quá nhiều dữ liệu mà một số lượng nhỏ máy không thể xử lý được.
Ngày nay, có ba loại dữ liệu phổ biến: có cấu trúc, không cấu trúc và bán cấu trúc. Có cấu trúc đề cập đến dữ liệu được hiển thị trong các bảng được xác định rõ ràng, không có cấu trúc, bao gồm các điểm dữ liệu như thông tin đăng nhập, số lần nhấp vào trang web, lượt xem trang hoặc lượt xem video và dữ liệu bán cấu trúc, có chứa sự kết hợp giữa có cấu trúc và không cấu trúc.
Tiếp theo, chúng ta sẽ nói về sáu chữ V của dữ liệu lớn.
“Vs” của dữ liệu lớn là gì?
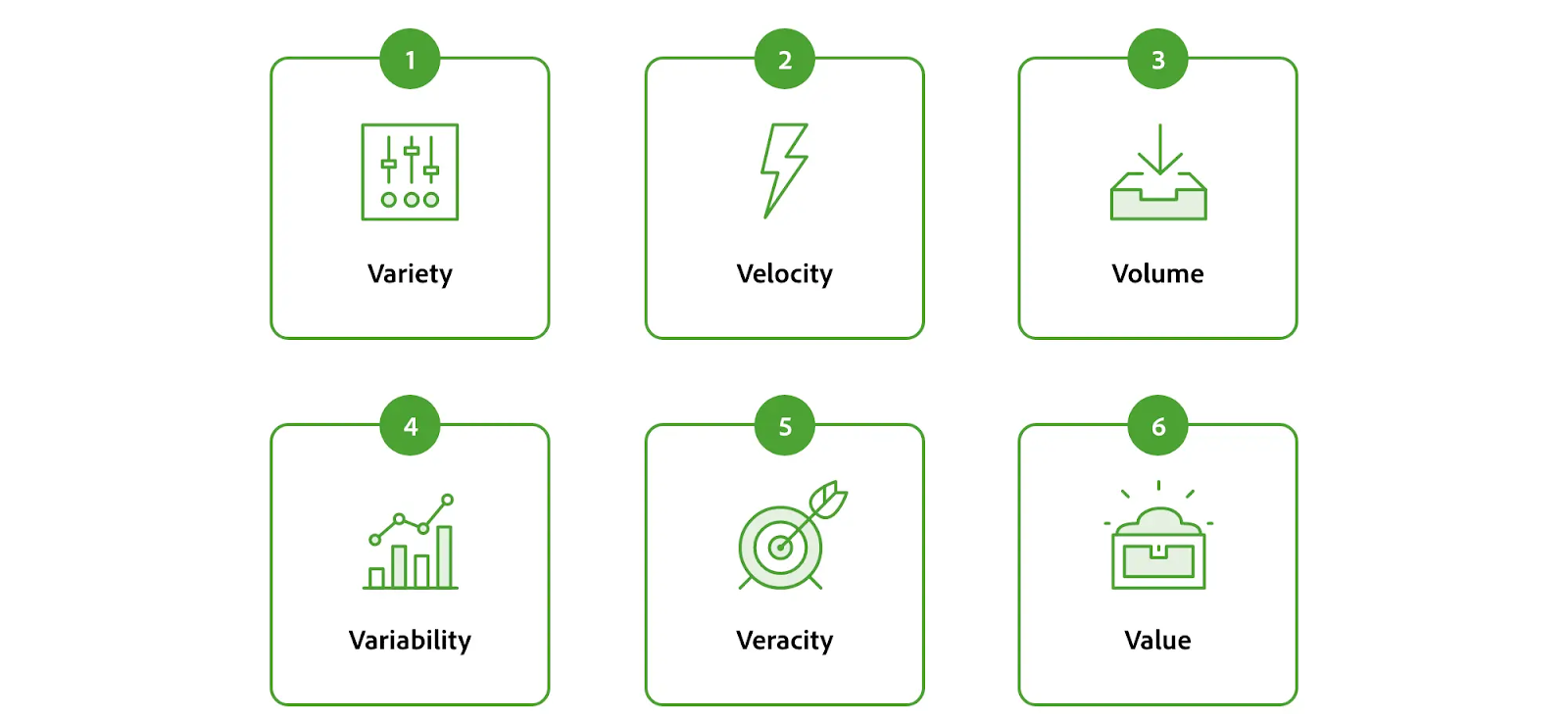
Ba đặc điểm chính của dữ liệu lớn được gọi một cách dễ dàng là ba chữ V: tính đa dạng, vận tốc và khối lượng.
- Sự đa dạng có nghĩa là thành phần khác nhau của các tập dữ liệu. Dữ liệu có cấu trúc, không cấu trúc và bán cấu trúc là những ví dụ về sự đa dạng trong dữ liệu.
- Vận tốc mô tả tốc độ cung cấp dữ liệu cho tổ chức thu thập dữ liệu đó. Ví dụ: Adobe thu thập hơn 250 nghìn tỷ giao dịch mỗi năm, tương đương khoảng 475 triệu giao dịch mỗi phút.
- Khối lượng đề cập đến lượng dữ liệu thuần túy được thu thập. Nếu người đăng ký YouTube tải lên 380.000 giờ dữ liệu mỗi giờ thì đó là một lượng dữ liệu lớn. Nếu một tổ chức đang xử lý 380.000 email mỗi giờ thì khối lượng dữ liệu sẽ ít hơn đáng kể nhưng tốc độ vẫn cao.
Theo thời gian, ba chữ V này đã mở rộng thành sáu chữ V để bao gồm tính biến thiên, tính xác thực và giá trị. Những người trong chúng ta đánh giá cao các công cụ ghi nhớ sẽ cảm ơn bất cứ ai nghĩ ra sáu từ mô tả, tất cả đều bắt đầu bằng chữ V.
- Tính biến đổi liên quan đến việc thiết lập bối cảnh và hiểu cách dữ liệu liên tục thay đổi. Nếu cùng một quá trình liên tục cho ra một kết quả khác thì đó là sự biến thiên.
- Tính xác thực đề cập đến độ chính xác. Dữ liệu không đáng tin cậy là dữ liệu vô dụng.
- Giá trị là đỉnh cao của năm Vs trước đó. Đó là lợi nhuận mà công ty của bạn nhìn thấy từ dữ liệu.
Bây giờ chúng ta đã khám phá dữ liệu lớn là gì, hãy cùng tìm hiểu lý do tại sao nó lại quan trọng đến vậy.
Tại sao dữ liệu lớn lại quan trọng?
Ngày nay, các công ty phải khai thác sức mạnh của dữ liệu lớn để hiểu được bức tranh toàn cảnh về những gì khách hàng nghĩ và hướng đi kinh doanh của họ. Tổ chức càng có nhiều dữ liệu thì họ càng có thể đưa ra những quyết định sáng suốt hơn. Các công ty muốn hiểu cách khách hàng tương tác với thương hiệu của họ và đối với các tổ chức có lượng khán giả toàn cầu khổng lồ, điều đó đòi hỏi khối lượng dữ liệu lớn.
Một ứng dụng ngày càng quan trọng của dữ liệu lớn là hiểu rõ hơn nhu cầu của khách hàng. Cung cấp trải nghiệm khách hàng hàng đầu và phát triển để đáp ứng nhu cầu của khách hàng không phải là nhiệm vụ đơn giản hay dễ dàng. Các tổ chức cần hiểu khách hàng của họ đến từ đâu, họ làm gì trên trang web, họ dành bao nhiêu thời gian trên trang web và tần suất họ hoàn tất giao dịch hoặc chuyển đổi.
Dữ liệu hành vi được thu thập từ hành vi của khách hàng trên các trang web và các kênh khác như điện thoại di động, email, v.v. Thông tin giao dịch và thông tin cá nhân cũng có thể được thu thập. Hiểu được dữ liệu này có thể cung cấp cho bạn những hiểu biết quan trọng về cách cải thiện tốc độ bán hàng và cách tối ưu hóa các tương tác kỹ thuật số khác nhau. Nhiều quyết định xung quanh việc tối ưu hóa phụ thuộc vào lượng dữ liệu có sẵn và những hiểu biết sâu sắc có thể được rút ra từ dữ liệu đó.
Trong phần tiếp theo, bạn sẽ tìm hiểu cách hoạt động của dữ liệu lớn.
Dữ liệu lớn hoạt động như thế nào?
Vòng đời dữ liệu bắt đầu bằng việc thu thập thông tin từ các nguồn dữ liệu và kết thúc bằng việc lấy thông tin chi tiết từ dữ liệu được thu thập. Việc thiết lập chiến lược xung quanh dữ liệu lớn của bạn là rất quan trọng khi bắt đầu để bạn hiểu mục tiêu của mình ở từng giai đoạn.
Tích hợp dữ liệu lớn
Bước đầu tiên, thu thập dữ liệu, bao gồm việc tạo cơ sở hạ tầng để thu thập tất cả các điểm dữ liệu đến. Cơ sở hạ tầng sẽ phụ thuộc vào loại dữ liệu, nhưng dữ liệu thô luôn tồn tại ở đâu đó để có thể tiến hành phân tích sâu hơn khi cần.
Trong bước này, bạn sẽ cần tích hợp việc thu thập dữ liệu từ nhiều nguồn và ứng dụng khác nhau. Điều này yêu cầu thu thập, xử lý và định dạng dữ liệu một cách chính xác để các nhà phân tích dữ liệu của bạn có thể bắt đầu làm việc.
Quản lý dữ liệu lớn
Câu hỏi tiếp theo là làm thế nào để lưu trữ và sắp xếp dữ liệu. Việc xác định nơi dữ liệu sẽ tồn tại và cách lập danh mục dữ liệu để các hệ thống khác biết rằng nó tồn tại cũng quan trọng không kém. Dữ liệu chỉ hữu ích khi siêu dữ liệu mô tả nó. Nếu một tổ chức có khối lượng dữ liệu lớn nhưng không có cách nào khám phá dữ liệu đó hoặc thông báo cho ai đó nội dung của dữ liệu đó thì dữ liệu đó sẽ không có lợi ích gì. Về lưu trữ, dữ liệu lớn thường được lưu trữ trên đám mây, mặc dù máy chủ là một tuyến phổ biến khác.
Phân tích dữ liệu lớn
Sau khi dữ liệu được lưu trữ và quản lý, dữ liệu có thể được phân tích để tìm hiểu thông tin chi tiết và mẫu. Những hiểu biết sâu sắc thu được từ phân tích dữ liệu lớn sau đó có thể được hiển thị trực quan để thông báo cho các bên liên quan về những phát hiện và đưa ra khuyến nghị cho các bước tiếp theo của tổ chức.
Đây là lúc bối cảnh công nghệ xử lý dữ liệu lớn xuất hiện. Điều này bao gồm các công cụ phân tích như Apache Spark hoặc Databricks, giúp quản lý lượng lớn dữ liệu được lưu trữ dễ dàng hơn cũng như các công nghệ dữ liệu lớn được xây dựng xung quanh việc nhắn tin, như Kafka, chuyên xử lý dữ liệu phát trực tuyến được tạo liên tục. Một tổ chức cũng có thể chọn xây dựng và quản lý khung tùy chỉnh của riêng họ.
Những lợi ích và thách thức của dữ liệu lớn là gì?
Điều quan trọng là phải xem xét những thách thức khi quyết định thực hiện chiến lược xoay quanh dữ liệu lớn tại công ty của bạn. Dưới đây chúng tôi sẽ giải thích một số ưu và nhược điểm phổ biến nhất để bạn biết điều gì sẽ xảy ra.
Những thách thức dữ liệu lớn
Thu thập dữ liệu là không đủ. Các tổ chức phải có khả năng truy cập, phân tích và định hình dữ liệu. Dữ liệu phi cấu trúc và bán cấu trúc thường khó làm việc. Nếu không được quản lý thích hợp, dữ liệu có thể làm tăng chi phí mà không thực sự mang lại bất kỳ giá trị nào. Bộ công nghệ phù hợp có thể giúp các công ty hiểu được dữ liệu của họ và có thể giúp xác nhận hoặc bác bỏ những cảm nhận ban đầu về việc thực hiện một hành động.
Quản lý dữ liệu lớn tốt hơn đi kèm với sự trưởng thành. Nếu một tổ chức bắt đầu khám phá dữ liệu lần đầu tiên, họ có thể muốn giảm tốc độ và đảm bảo rằng họ đang đặt đúng câu hỏi. Cũng có thể có những sai lệch hoặc bất thường trong dữ liệu, điều này có thể không rõ ràng khi lần đầu tiên sử dụng dữ liệu lớn.
Các công ty cũng phải cẩn thận về cách họ sử dụng dữ liệu họ thu thập được. Ví dụ: họ có thể thu thập thông tin nhận dạng cá nhân (PII) như số thẻ tín dụng hoặc địa chỉ email, nhưng họ có thể không muốn hoặc không được phép sử dụng thông tin đó cho một số hành động tiếp thị nhất định hoặc cung cấp thông tin đó qua các địa điểm không an toàn.
Việc có một khuôn khổ phù hợp để quản trị dữ liệu sẽ giúp ngăn ngừa những sai lầm khi truy cập và sử dụng dữ liệu không đúng cách, đồng thời duy trì việc tuân thủ các quy định bằng cách đảm bảo rằng dữ liệu được dán nhãn phù hợp với mục đích sử dụng.
Lợi ích dữ liệu lớn
Ngược lại, có nhiều mặt tích cực khi khai thác sức mạnh của dữ liệu lớn tại công ty của bạn. Đầu tiên, bạn có thể mong đợi các hoạt động được cải thiện. Với các công cụ phân tích dữ liệu phù hợp, bạn có thể tối ưu hóa quy trình kinh doanh, hợp lý hóa nguồn lực và giảm chi phí.
Đôi khi, chìa khóa để bảo vệ công ty của bạn khỏi lãng phí hoặc gian lận nằm ngay trong dữ liệu. Dữ liệu lớn có thể hiển thị cho bạn các mẫu và thông tin chi tiết có thể không bị phát hiện. Với phân tích dữ liệu, bạn có thể chủ động và giảm thiểu rủi ro.
Ngày nay, có vẻ như cách nhanh nhất để chạm đến trái tim khách hàng là thông qua việc cá nhân hóa trên tất cả các nền tảng. Với dữ liệu lớn, các công ty có thể tìm hiểu thêm về hành vi của khách hàng và cá nhân hóa sản phẩm một cách phù hợp trong các chiến dịch tiếp thị của họ.
Cuối cùng nhưng không kém phần quan trọng, dữ liệu lớn mang lại cho bạn lợi thế cạnh tranh so với các công ty khác trong ngành của bạn. Bạn sẽ có kiến thức nội bộ về xu hướng và hiểu biết sâu sắc về thị trường, giúp bạn nhanh nhẹn thích ứng nhanh chóng với nhu cầu luôn thay đổi của khách hàng.
Tiếp theo, chúng ta sẽ xem xét một số trường hợp sử dụng dữ liệu lớn.
Một số trường hợp sử dụng dữ liệu lớn phổ biến là gì?
Không còn cách nào khác – các nhà lãnh đạo phải hiểu chiến lược tổng thể về mức độ ảnh hưởng của dữ liệu lớn đến từng bộ phận và lộ trình sản phẩm tổng thể của bạn.
Một số trường hợp sử dụng này bao gồm:
- Hoạt động – Bạn có thể sử dụng dữ liệu lớn để tối ưu hóa chuỗi cung ứng của mình thông qua dự báo nhu cầu, quản lý hàng tồn kho theo thời gian thực và bảo trì dự đoán.
- Học máy – Dữ liệu lớn có thể đào tạo các mô hình học máy để phân tích dự đoán. Càng có nhiều dữ liệu truy cập thì dự đoán càng chính xác.
- Bảo mật – Phát hiện các mối đe dọa đối với thông tin bí mật và gian lận dưới mọi hình thức bằng cách tận dụng dữ liệu lớn và áp dụng thuật toán học máy.
- Phát triển sản phẩm – Bạn có thể sử dụng dữ liệu lớn để thông báo cách sản phẩm của bạn phát triển. Các phân tích như thị trường thử nghiệm, nhóm tập trung và phương tiện truyền thông xã hội có thể cực kỳ hữu ích để hiểu — và nhấn mạnh — những điểm yếu của khách hàng.
Bây giờ bạn đã hiểu rõ hơn về các trường hợp sử dụng sâu rộng của dữ liệu lớn, hãy xem qua một số phương pháp hay nhất để tạo chiến lược dữ liệu lớn tốt nhất có thể.
Một số thực tiễn tốt nhất về dữ liệu lớn quan trọng là gì?
Trên hết, điều quan trọng là phải tiếp cận dữ liệu lớn một cách có chiến lược để công ty của bạn sử dụng nó với tiềm năng tối đa.
Các phương pháp hay nhất cần xem xét có thể bao gồm:
- Hãy chậm lại và đặt những câu hỏi phù hợp. Quản lý dữ liệu lớn tốt hơn đi kèm với sự trưởng thành. Nếu một tổ chức bắt đầu khám phá dữ liệu lần đầu tiên, họ có thể muốn giảm tốc độ và đảm bảo rằng họ đang đặt đúng câu hỏi.
- Tối ưu hóa quản lý chất lượng dữ liệu. Thu thập dữ liệu là không đủ. Các tổ chức phải có khả năng truy cập, phân tích và định hình dữ liệu. Dữ liệu phi cấu trúc và bán cấu trúc thường khó làm việc. Nếu không được quản lý thích hợp, dữ liệu có thể làm tăng chi phí mà không thực sự mang lại bất kỳ giá trị nào.
- Áp dụng các biện pháp kiểm soát để đảm bảo bạn tuân thủ quy định. Các công ty thường có nghĩa vụ theo hợp đồng nêu rõ họ có thể lưu giữ dữ liệu trong bao lâu. Các nghĩa vụ hợp đồng này sẽ thay đổi khá nhiều và được điều chỉnh bởi các quy định ở các vị trí địa lý khác nhau. Khách hàng cũng có thể yêu cầu xóa dữ liệu của họ. Khi có những yêu cầu này, các công ty phải đảm bảo rằng họ loại bỏ mọi dữ liệu có thể liên quan đến khách hàng đó trong hệ thống của mình để có thể tuân thủ các quy định về quyền riêng tư.
Trong phần cuối của bài viết này, chúng ta sẽ xem xét tương lai không xa của dữ liệu lớn.
Việc sử dụng dữ liệu lớn sẽ tiếp tục phát triển như thế nào?
Một xu hướng sử dụng dữ liệu lớn là tốc độ cung cấp thông tin chi tiết, đưa ra quyết định và thực hiện hành động ngày càng tăng.
Các công ty cần phản ứng với hành vi của khách hàng trong thời gian thực. Nhiều năm trước, các tổ chức có thể xem xét dữ liệu họ đã thu thập trong 24 hoặc 48 giờ, nhưng giờ đây, các tổ chức phải phản hồi ngay lập tức, điều này đòi hỏi công nghệ phải chạy các truy vấn đối với lượng lớn dữ liệu khi có sẵn.
Có một sự thay đổi đáng kể đang diễn ra trong thế giới dữ liệu lớn khi nó chuyển từ cách suy nghĩ theo định hướng hàng loạt về mọi thứ sang cách diễn ra trong thời gian thực. Học máy và trí tuệ nhân tạo (AI) là công cụ giúp tăng tốc độ phân tích dữ liệu lớn.
Được hỗ trợ bởi Adobe Sensei, Adobe Analytics sử dụng AI để cung cấp những hiểu biết mang tính dự đoán dựa trên toàn bộ phạm vi dữ liệu của bạn. Khi bạn đã sẵn sàng bắt đầu, Analytics sẽ biến dữ liệu theo thời gian thực thành thông tin chi tiết theo thời gian thực.

{kind=link}